Тема обширная и не особо простая, так что если лень/некогда/нет желания заморачиваться, читать много букаф, думать и разбираться то первым и самым главным вашим действием должно быть добавление в закладки, в вашем браузере, сайта hashrate.no
На нем можно найти среднестатистический разгон практически на любую карту, под практически любую монетку.
Если hashrate.no уже у вас в закладках, но разобраться все же хочется, и многабукаф не страшит - читаем следующую часть
Как вы все знаете, майнинг - это некий процесс связанный с некими вычислениями (про матчасть по процессу пост тоже будет ![]() ). В GPU мамкинге можно выделить три основных типа алгоритмов: core intensive, memory intensive и смешанный. Мы разберем их отдельно, для начала нам нужно усвоить несколько общих вещей:
). В GPU мамкинге можно выделить три основных типа алгоритмов: core intensive, memory intensive и смешанный. Мы разберем их отдельно, для начала нам нужно усвоить несколько общих вещей:
- силиконовая лотерея (silicon lottery) понятие означающее, что каждая карта индивидуальна, даже две одинаковых модели, даже одного вендора, даже из одной партии будут держать разный разгон, т.к. в природе не существует двух абсолютно идентичных чипов и прочих элементов (:
- разгон видеокарты в мацнинге это не совсем разгон в прямом смысле, чаще нам нужно добиться именно стабильности и приемлемого потребления/нагрева, а не максимального хэшрэйта.
- офсет (offset) - смещение, т.е. добавление (или убавление) к уже существующей частоте.
- лок (lock) фиксация частоты на определенном значении.
- пл (pl/power limit) лимит потребления видеокарты в который она должна уложиться.
пл используется для того, чтоб карта не выходила за определенный порог потребления, ну и не грелась как пукан мацнера при постоянных ребутах фермы (:
использовать пл имеет смысл если у вас нет четких локов ядра (ну и вольтажа на красных) тогда карта не будет жрац больше того, что вы указали, регулируя свою частоту самостоятельно.
лок ядра используют для фиксации частоты на определенном значении (ну и вольтажа заодно на зеленых), при локе ядра (и вольтажа на красных) нет смысла использовать пл, ибо карта может войти в диссонанс и отвалиться, что чревато ребутами ригов и горящим пуканом ![]()
лично я пл не использую вообще, всегда все делаю через лок, чего и вам советую ![]()
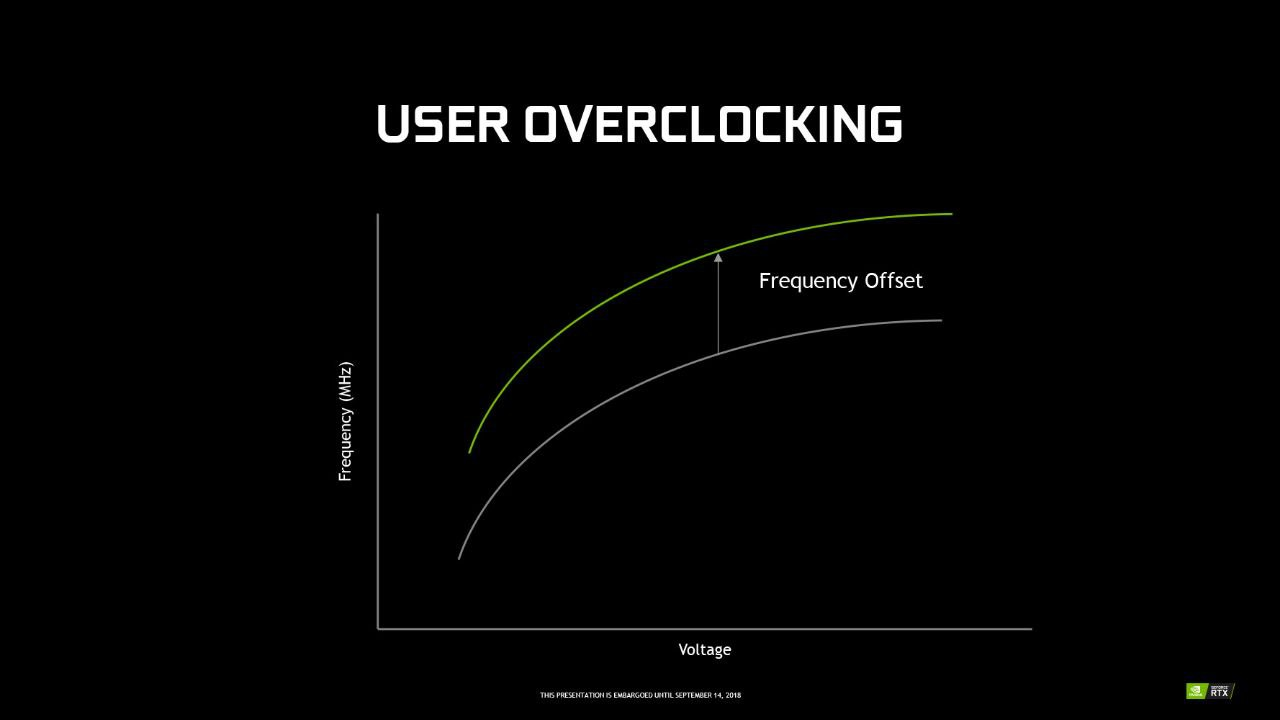
офсет, вот тут все интересней. Когда мы лочим частоту на зеленых картах, у них лочится вольтаж на определенном значении под эту частоту, кто игрался с curve в афтербернере думаю поймет и так, и вот офсетом, мы можем увеличивать частоту ядра не увеличивая его вольтаж и соответственно потреб! Это позволяет накинуть лишних мегагерц, а за одно и мегахэшэй на ядерных/смешанных алго при одном и том же потреблении, либо снизить вольтаж (на практике именно так) и потребление оставшись на заданной частоте (смотря в какую сторону офсет)
пример из жизни:
использовав лок частоты ядра в рэйве командой прописанной в set “oc --fixclk 1740” мы лочим частоту И вольтаж на ядре, а добавив офсет “-cclk 250” (или просто написав офсет в UI системы на вкладке tuning) мы останемся на частоте 1740, при этом снизив вольтаж и соответственно потребление.
Но тут силиконовая лотерея проявит себя во всей красе и офсет который будут держать две одинаковые карты будет отличаться порой довольно сильно.

начнем пожалуй с memory intensive алго, ибо с него, скорей всего, и начался увлекательный путь в мир мамкинга у большинства ![]()
К memory intensive относятся такие алго как ethash (он же dagger hashimoto), etchash, autolykos, octopus и т.п.
Всех их объединяет то, что следуя из названия, все они используют для расчетов только память видеокарты, минуя ядро.
Memory intensive алгоритмы задумывались как защита от ASIC’ов, для бОльшей децентрализации сети, и на радость нам хомякам GPU майнерам. Но, что-то пошло не так, и ASIC на кефир все же имеется.
Фэйл?
Не совсем.
Асики на memory intensive алго не на много эффективней и быстрей карт (по крайней мере по сравнению с ядерными) ибо памяти быстрей GDDR6X, например, на данный момент (04.2023) не придумали, а вся скорость и эффективность асиков достигается чисто за счет дублирования канала, разгона шины до предела и исключения из этой цепочки сопсна ядра (:
Увеличение хэшрэйта на данных алго достигается за счет разгона частоты видеопамяти.

core intensive алго производят вычисления чисто на GPU (да и любом другом процессоре который умеет в вычисления) минуя работу с видеопямятью.
К таким алго относятся все разновидности sha, blake, cryptonight, kHeavyHash и т.п.
Данные алго потребляют гораздо меньше ватт на хэш и вообще совсем не защищены от ASIC’ов, а чаще даже специально под них и сделаны, любая монета на core intensive алгоритме, имея хоть какой-то коммерческий успех, рано или поздно перестанет быть интересной нам, хомякам GPU мацнерам, в связи с выходом на нее сначала прошивки под FPGA, а позже и сопсна ASIC’ов, (ох уж эта каспа!) но вполне может порадовать нас на старте ![]()
Увеличение хэшрэйта на таких алго достигается за счет разгона ядра, а отключение даунвольт памяти при этом, позволит увеличить энергоэффективность, за счет снижения потребления памятью видеокарты.
И да, memory intensive и core intensive алгоритмы чаще всего можно мацнить в дуале!
И остались у нас смешанные алго и сопсна дуал. Смешанные самые противоречивые. С одной стороны, они максимально защищены от ASIC’ов, т.е. с вероятностью 99%, даже если монетка будет иметь офигенный коммерческий успех, ASIC на нее все равно не появится, и радовать она будет только нас (GPU мамкеров), но с другой - это самые горячие, требовательные и прожорливые алго насилующие наши видеокарты (и счета за электроэнергию) на уровне дуала. Самые требовательные к охладу карт алгоритмы. К таким алго, например, относятся все разновидности KawPow.
Хэшрэйт, как вы понимаете, поднимается на таких алго за счет разгона и памяти и ядра, так же как и с дуалом.
Итак, с типами и терминами разобрались, перейдем к примерам и практике
что же на практике? а на практике если хочется добиться идеальных показателей по хэшрэйту/потреблению придется работать не меньше, чем кот на заводе ![]()
Но, как вы уже поняли, есть определенный алгоритм действий для индивидуального разгона под определенную монетку.
Для memory intensive алго нам нужно максимально разогнать память, при этом максимально уменьшив потребление ядра, но так, чтоб карте хватало на стабильное питание памяти.
Тут можно начать с офсета по памяти в 2000 (на виндовс делим пополам - 1000) и понемногу, например с шагом в 10-50 поднимать. И либо фиксить ядро на уровне 1200, постепенно поднимая его и смотря соотношение хэш/ватт, либо не трогая ядро играть с пл. Офсет ядра тут нам ничего не даст, его можно не трогать совсем.
итого выйдет что-то типа 1440 ядро, 2230 память (либо 2230 память и 110пл) - это просто пример, помните про силиконовую лотерею ![]()
пример:
команда для рэйва в set:
oc --fixclk 1440 --mclk 2230
для core intensive алго уже играть придется с двумя параметрами, с локом и офсетом ядра, т.к. память нам не нужна ее просто лочим на минимальном уровне (обычно это 810 на зеленых не специфичных) и забываем о ее существовании.
Идем смотрим спецификацию своей карты, а именно максимальную частоту ядра, убираем из нее для начала 300mhz и лочим это значение, офсет можно начать с 90-100 и с шагом 10-50 увеличиваем/уменьшаем и то и другое, пока снова не добьемся идеального соотношения хэшей на ватт.
выйдет в итоге что-то типа: лок памяти 810, лок ядра 1770, офсет ядра 230 - это просто пример ![]()
пример:
команды рэйва в set:
oc --fixclk 1740 --fixmclk 810 --cclk 230
ну и, как вы уже наверное догадались, для смешанных алго и/или дуала нужно играть всеми параметрами добиваясь лучших значений хэш на ватт. Там уже не будут максималки по ядру, но вполне возможны по памяти. и выйдет что-то типа: офсет памяти 2210, лок ядра 1605, офсет ядра 210 - это просто пример ![]()
не бойтесь эксперементировать!
карта от переразгона точно не умрет, вот ребутов фермы/майнера, прожженых кресел и штанов будет по началу не мало.
Что нам это даст в итоге:
- понимание как все работает.
- идеальный разгон под каждую вашу карту.
- приемлемые температуры и счета за ээ
- отсутствие нужды в выпрашивании батников.
- титул “гуру разгона” +10 int